


Debug-gym: Microsoft dạy AI gỡ lỗi code như lập trình viên
Microsoft dạy AI gỡ lỗi code thông qua một công cụ mới mang tên debug-gym – môi trường huấn luyện giúp các công cụ AI không chỉ viết mã, mà còn học được kỹ năng sửa lỗi tương tác như con người. Dự án này phản ánh thực tế trong phát triển phần mềm hiện đại: viết code đã có AI hỗ trợ, nhưng sửa lỗi vẫn là “gánh nặng” lớn cho lập trình viên.
Microsoft dạy AI gỡ lỗi. Giờ Đây AI không chỉ viết code mà còn phải sửa code
Theo CEO GitHub, Thomas Dohmke, đến năm 2023, 80% lượng code có thể sẽ do Copilot viết. Trong khi đó, Garry Tan từ Y Combinator còn tiết lộ 95% mã trong nhiều startup mới của họ được tạo ra từ các mô hình ngôn ngữ lớn (LLM).
Tuy nhiên, phần lớn thời gian của lập trình viên không nằm ở khâu viết mã, mà là xử lý lỗi. Vậy tại sao không huấn luyện AI cũng làm được điều đó?
Debug-gym là gì?
Debug-gym là một môi trường được thiết kế để huấn luyện AI sửa lỗi mã nguồn theo cách con người làm, tức là theo quy trình: đưa giả thuyết, kiểm tra dòng lệnh, quan sát giá trị biến, và lặp lại đến khi vấn đề được xử lý.
Khác với các công cụ AI hiện tại chỉ dựa vào thông báo lỗi và dữ liệu huấn luyện để “đoán lỗi”, debug-gym cho phép AI tương tác trực tiếp với các công cụ như pdb, eval, view, rewrite, listdir, mở rộng khả năng quan sát và hành động như một lập trình viên thực thụ.
Điểm nổi bật của debug-gym
- Hỗ trợ cấp độ toàn repository: AI có thể truy cập, điều hướng và chỉnh sửa toàn bộ mã nguồn trong một dự án.
- An toàn và cách ly: Thực thi mã trong môi trường Docker sandbox để đảm bảo kiểm soát rủi ro.
- Mở rộng dễ dàng: Dễ tích hợp thêm công cụ hoặc thay đổi cấu trúc hành động.
- Tương thích LLM hiện đại: Giao tiếp qua định dạng văn bản có cấu trúc (JSON) và cú pháp đơn giản.
Debug-gym còn hỗ trợ kiểm thử với các benchmark như:
- Aider: kiểm tra sửa lỗi cấp độ hàm
- Mini-nightmare: mã lỗi đơn giản, ngắn gọn
- SWE-bench: lỗi thực tế yêu cầu hiểu rõ toàn bộ mã dự án (dạng pull request GitHub)
Thử nghiệm đầu tiên: Tín hiệu tích cực
Microsoft sử dụng một agent đơn giản dựa trên prompt để kiểm thử, tích hợp các công cụ debug và thử trên 9 mô hình LLM khác nhau. Kết quả cho thấy khi có công cụ gỡ lỗi, hiệu suất sửa lỗi trên bộ dữ liệu SWE-bench Lite tăng rõ rệt, với mức tăng từ 30% đến 180% so với khi không có công cụ.
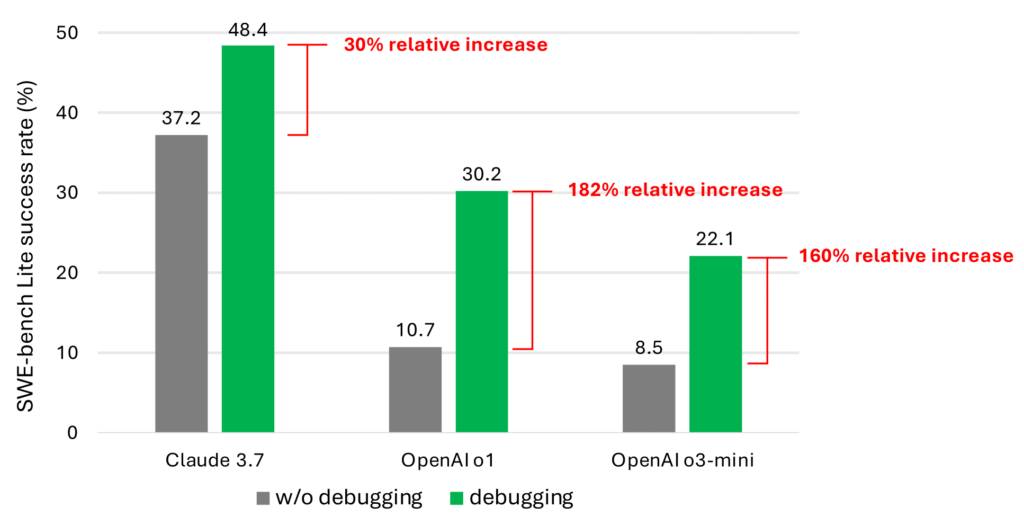
Tuy nhiên, độ khó vẫn còn cao vì thiếu dữ liệu huấn luyện theo trình tự gỡ lỗi (debug trace). Nhóm nghiên cứu tin rằng tương lai cần fine-tune mô hình AI theo hướng “tìm thông tin”, tức mô phỏng lại quy trình suy luận từng bước khi sửa lỗi thực sự.










